Introduction
The Internet
revolution rekindled the need for platform independence. C/C++ were not
suitable for such a task, and that's when Sun's Java came into the picture.
Java was officially launched by Sun in 1995. Java was introduced as a platform
independent, true Object-Oriented language. The objective of this article is to
explain how Java achieves its platform independence. But this can not be
understood completely without a good understanding of Compiled and Interpreted
languages; and hence the article also sheds some light on compilers and
interpreters. The article also goes on to explain JVM (Java Virtual
Machine) and CLR (Common Language Runtime, which is the runtime environment of
Microsoft's .NET technology). Any discussion on JVM and CLR would not be
meaningful without discussing Just-In-Time (JIT) compilation - a concept also
discussed in the article.
The article is not
intended to be an exhaustive study on JVM, CLR, JIT, Compilers or Programming
languages. It is intended to give a big picture of how these bits and pieces
are glued together to achieve platform independence. Interested readers should
consult the references given at the end to find out more about the topics
discussed in this article.
Table of Contents
- How do computers work ?
- What are compilers ?
- What are interpreters ?
- Pros and Cons of compiler and interpreted languages ?
- Platform dependence issues in compiler languages ?
- How does a Java program work ?
- What is the Java Virtual Machine (JVM) ?
- What is Common Language Runtime (CLR)?
- Conclusion
Computer hardware is
like any other machinery. You can switch it on, and electrons will start
flowing through it. That's all that a computer can do. Like an ignorant being -
computer needs to be told specifically what it should do. Computer programs are
the tool to tell the computer what you want it to do.
Computers understand
only one language - the machine code. Machine code is a sequence of binary (1
and 0) digits. A microprocessor manufacturer (the microprocessor is the heart
of a computer) decides which sequence of bits means what.
Imagine that you want
to construct your own microprocessor. You will incorporate various tasks in it.
And you need to have a unique code for each task. A computer program will issue
these codes to initiate the required task of the microprocessor.
Let us consider the
very basic task of moving a value into a register (a register may be thought of
a microprocessor's extremely fast internal memory). This task requires the
microprocessor to read the value from a specific memory address and to put it
in a specific register. Your microprocessor thus needs to know the following:
- The specific operation code
- The memory address from where to
read the value
- The register number where to put
the value.
Remember that
microprocessors are built so that can only apply operations on the contents of
registers and not on the memory directly. It is for this reason that we have to
move numbers into the registers from the memory before we can apply various
operations on them e.g. addition, subtraction, division etc. So a move operation is one of the mostly used and basic operation in
a microprocessor.
Let us assign a
suitable operation code to the move operation -
"0001". Do you see any problems with this code? There is nothing
wrong with our choice of code except that it is only 4 digits wide. This would
only allow our microprocessor to have 24 = 16 operations. Obviously
we would need much more than 16 operations to make our microprocessor
commercially viable. So let us change our code for the move
operation and assign it a bigger value - "0000 0000 0001". Now our
processor can handle 212 = 4096 operations.
Having decided on the
operation code (op code), we need to decide on the memory address.
If the computer has
512 bytes of RAM (way too small from today's standards, but this is enough for
illustration purposes ), and a single location of RAM is 2 bytes (16 bits)
wide, then we have -- 512 bytes / 2 bytes -- 256 bytes of addressable memory
locations, and would require -- 28 = 256 -- at least 8 bits to
represent a memory address.
Let us assume that
our microprocessor has 16 internal registers, we would therefore need 24
= 16, 4 bits to specify a register.
With the above three
design decisions, if a program wants a number to be moved from RAM into a
register then it would have to issue the following machine code to our
microprocessor:
0000
0000 0001
0000 0011 0010
The first 12 bits
identify the op code, the next 8 bits identify the memory address and the next
four bits identify the register number. The above machine code will have move
the number kept in memory location "3" into register number
"2".
Remember that Machine
language is the only language that the Microprocessor (hence the Computer)
understands. So ALL the applications/software will ultimately have to be
translated into Machine language before they can run on a Computer.
Although our
microprocessor is a simple one, and today's commercial microprocessors are all
built on the same principle. Every microprocessor has its own op codes (like
the move
op code of our simple microprocessor) and its own addressing schemes. Apple
Computer's are built around Motorola's microprocessors, while IBM and IBM compatible
computers are all built around Intel processors.
The microprocessor
that we have built in this section is the simplest possible. Visit [1]to find out about the latest microprocessor development
Let us use our simple
microprocessor and try to
do the simplest of task, namely adding two numbers. This task would requires
the following:
move
the first number from the memory to register # 1
move
the second number from the memory to register # 2
add
the contents of register #1 to the contents of register # 2 and put the result
in register # 3
move
the contents of register # 3 to memory.
We had made a sample
machine language code for move operation in the
above section. Our move operation could move a number from
memory to the register. We would also need another move
operation that does the opposite - i.e. move a number kept in a
register to a memory location. We will use the following machine code for such
an operation:
0000
0000 0010
0001 0000 0011
The first 12 bits are
the op code, the next four bits are the register number and the remaining 8
bits are the memory location. Note that this move operation code is
0000 0000 0010 (equal to "2").
Next we need to
design a code for the add operation.
0000
0000 0011
0001 0010 0011
With the above
machine codes we can instruct our computer to perform the addition task as
given below:
Instruction 1
0000 0000 0001 0000 0011 0001 (moving the number from memory location "3" to register #1)
0000 0000 0001 0000 0011 0001 (moving the number from memory location "3" to register #1)
Instruction 2
0000 0000 0001 0000 0100 0010 (moving the number from memory location "4" to register #2)
0000 0000 0001 0000 0100 0010 (moving the number from memory location "4" to register #2)
Instruction 3
0000 0000 0011 0001 0010 0011 (Adding register #1 and register # 2, and putting the result in register #3)
0000 0000 0011 0001 0010 0011 (Adding register #1 and register # 2, and putting the result in register #3)
Instruction 4
0000 0000 0010 0011 0000 0100 (Moving the contents of register # 3 in memory location "4")
0000 0000 0010 0011 0000 0100 (Moving the contents of register # 3 in memory location "4")
The above machine
code will instruct the computer to add two numbers.
The CPU will execute
the first statement and will then increment its Program Counter Register
this register keeps the memory address of the next instruction to execute, so
that now this register points to the next instruction (i.e. instruction 2).
Now the CPU will
fetch the instruction from the RAM into its cache/registers and execute it.
Once executed the same process will be repeated for the next instruction -
until the complete program (i.e. all the machine language instructions have
been executed); at which point the control is given back to the operating
system. This sequence of operation is called a fetch-execute cycle and
is a characteristic of Von-Neuman architecture (the architecture around which
all today's PCs are built). It should be noted that the execution of an
instruction takes far less time than the fetch process. This is because the
execution is implemented through hardware, while the fetch involves moving the
data back an forth from and to memory and cache/register. So in a compiled code
the bottle neck is the fetch operation.
Every microprocessor
has its own machine code. Our extremely simple microprocessor had its own
machine code, Intel would have its own code and so would Motorola.
For human being it is
almost impossible to remember the machine code and to develop even a small
application using machine codes. That's where the higher level languages come
in.
In C/C++, to add two
numbers you would write the following code:
int
i;
int
j;
int
k;
k = i + j;
Compare the C code
with the machine code. It is far more viable to write applications in a high
level language like C/C++ then to write the same application in machine
language. But the problem is that the computer would not understand anything
but the machine language - what we need is some sort of a translator that will
take the High level C/C++ code and translate it into machine code. Such a
"translator" is called a compiler.
The compiler is a
program that takes in the C/C++ file(s) as an input and outputs an executable
file, that can then be directly run on the host computer.
As I already
mentioned the existence of multiple (and incompatible) microprocessors, this
means that we will have separate compilers for separate hardware. Thus the same
C code will have to be compiled using a C-compiler for Apple Macintosh in order
to run on the Apple Computer. If you want the same C code to run on Microsoft
Windows running on the Intel platform, then you will have to compile your C
code using the C-compiler for Windows.
Simply put a compiler
converts a source code file (which is a simple text file) into an executable
file that can be run on the host computer. Those familiar with C/C++ will
realize that this is an over simplification.
Your C/C++ code is
not directly converted into .exe file; but is converted into an intermediate
file called an object file (.obj). If you have five C/C++ files in your project
then the compiler would generate five obj files, one for each C/C++ file; but
only one .exe file. The object file is at a slightly higher level than the raw
.exe file. In an object file the memory references are local, and the obj file
is not linked to other obj, dll, lib files that your C/C++ program uses.
When you use the
include statement #include <myfile.h> in your C/C++, the compiler checks for
the existence of myfile.h file. If it does not find it you are given an
error message and the compilation fails. Imagine that the file myfile.h
exists, and you have used a function addNumber(int, int)
that has been declared in myfile.h. The compiler will check to see if
the function has been declared in myfile.h. If the function does not
exist then the compilation will fail with an error message. Imagine that the
function has been declared in myfile.h. Now the compiler would
successfully finish compilation - unless there is some other error.
After successful
compilation, the compiler will generate an obj file, and will initiate the
linker. The linker is a program that takes in all the obj files in your project
and looks for all the cross-referenced files, and all the needed libraries. In
our example above, the compiler ensures that myfile.h exists. The linker
ensures that the .lib file of myfile.h must also exist. The lib file is
the file that contains the code of all the functions declared in myfile.h.
Another important task that the Linker does is to translate operating system
API (Application Programming Interface) calls to appropriate memory addresses.
Many operating systems provide I/O APIs. So the programmer need not reinvent
the wheel, instead in our programs we simply make function calls to such
operating system's API functions. The linker knows the memory addresses where
the code to these functions reside, and translates the function calls to
appropriate memory address with in the operating system memory space.
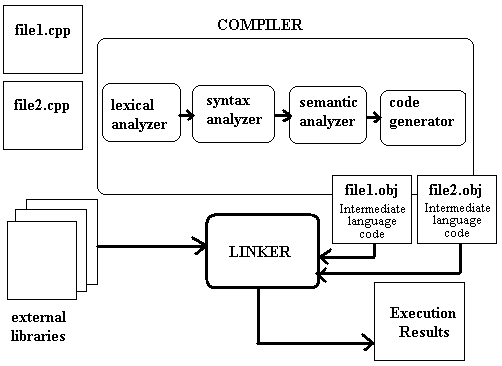
I will not discuss
lexical, syntax, semantic analyzers, and code generator. Interested readers
should see the reference section for details on these topics.
If compilers are one
extreme to running programming languages then pure interpreters are the other
extreme. Pure interpreters do not do any code translation as done by compilers.
These interpreters take the source code ( which is written in a high language)
and start executing the statements on the host machine, one by one. These pure
interpreters are unable to do any code optimizations at all. Pure interpreters
are also unable to do the syntax check; as is done by compilers. Example of
pure interpreters are the scripting languages that come with all the operating
systems. The shell scripts in Unix/Linux, the batch files (.bat) and the
command files (.cmd) in Microsoft Windows are all examples of pure interpreted
languages. When you make a batch file you simply write the high level code, and
save the file with a .bat extension. To run your .bat file you simply type the
name of the file on the command prompt. The operating system reads the first
line of the file and (tries to) execute the first statement. If the execution
is successful you get the desired results, if the execution can not be carried
out due to a syntax error, you will see "Bad command or file name"
error message on the command prompt window. The same applies to the shell
scripts written in Unix/Linux.
Some of the
commercial programming languages have been known to be interpreted e.g. BASIC,
Java, Tcl/TK. And yet these languages do not behave quiet like the description
given above. The reason is simple - none of the popular modern programming languages
are pure-interpreter based. They are either compiled (like C/C++) or adopt a
hybrid approach (like Java, BASIC, Tcl/Tk). The pure and hybrid approach may be
described by the following diagrams :
Pure Interpreter
SOURCE CODE --------> PURE INTERPRETER --------------> EXECUTION RESULTS
(Hybrid
compiler-interpreter)

As is obvious from
the above diagrams, today's popular interpreted languages are not
purely-interpreted. They follow the "compilation" technique to
produce an intermediate code (e.g. Microsoft's Intermediate Language - MSIL,
Sun's Java Byte Code etc.). It is this intermediate language that the
interpreter works on, and not the original high level source code. This
approach rids many of the problems inherent in pure-interpreted languages, and
gives many of the advantages of fully-compiled languages.
Readers should note
that both interpreters and compilers eventually convert the source code to
machine-language; after all the computer can only run a program in a machine
language. A compiler does this conversion off-line and in one go (as discussed
in the what are compilers section ); whereas the interpreter
does this conversion one-program statement-by-one. A compiled program runs in a
fetch-execute cycle whereas an interpreted program runs in a decode-fetch-execute
cycle. The decoding is done by the interpreter, whereas the fetch and
execute operations are done by the CPU. In an interpreter the bottleneck is the
decoding phase, and hence an interpreted program may be 30-100% slower than a
compiled program.
It is evident from above , that an interpreted program has an overhead of decoding
each statement one-by-one; thus in an interpreted program the bottleneck is the
decoding process.
The readers would be
asking themselves an obvious question "Why are some languages developed as
interpreted and others as compiled?. What are the advantages/disadvantages of
booth these approaches?" This is the topic of the next section.
Languages can be
developed either as fully-compiled, pure-interpreted, or hybrid
compiled-interpreted. As a matter of fact, most of the current programming
languages have both a compiled and interpreted versions available.
Both compiled and
interpreted approaches have their advantages and disadvantages. I will start
with the compiled languages.
Compiled languages
- One of the biggest advantages of
Compiled languages is their execution speed. A program written in C/C++
runs 30-70 % faster then an equivalent program written in Java.
- Compiled code also takes less
memory as compared to an interpreted program.
- On the down side - a compiler is
much more difficult to write than an interpreter.
- A compiler does not provide much
help in debugging a program - how many times have you received a
"Null pointer exception" in your C code and have spent hours
trying to figure out where in your source code did the exception occurred.
- The executable Compiled code is
much bigger in size than an equivalent interpreted code e.g. a C/C++ .exe
file is much bigger than an equivalent Java .class file
- Compiled programs are targeted
towards a particular platform and hence are platform dependent.
- Compiled programs do not allow
security to be implemented with in the code - e.g. a compiled program can
access any area of the memory, and can do whatever it wants with your PC
(most of the viruses are made in compiled languages).
- Due to loose security and platform
dependence - a compiled language is not particularly suited to be used to
develop Internet or web-based applications.
Interpreted languages
- Interpreted language provides
excellent debugging support. A Java programmer only spends a few minutes
fixing a "Null pointer exception", because Java runtime not only
specifies the nature of exception but also gives the exact line number and
function call sequence (the famous stack trace information) where the
exception occurred. This facility is something that a compiled language
can never provide.
- Another advantage is that
Interpreters are much easier to build then a compiler.
- One of the biggest advantages of
Interpreters is that they make platform-independence possible.
- Interpreted language also allow
high degree of security - something badly needed for an Internet
application.
- An intermediate language code size
is much smaller than a compiled executable code.
- Platform independence, and tight
security are the two most important factors that make an interpreted
language ideally suited for Internet and web-based applications.
- Interpreted languages have some
serious drawbacks. The interpreted applications take up more memory and
CPU resources. This is because in order to run a program written in
interpreted language; the corresponding interpreter must be run first.
Interpreters are sophisticated, intelligent and resource hungry programs and
they take up lot of CPU cycles and RAM.
- Due to interpreted application's
decode-fetch-execute cycle; they are much slower than compiled programs.
- Interpreters also do lot of
code-optimization, security violation checking at run-time; these extra
steps take up even more resources and further slows the application down.
C/C++ is a compiled
language i.e. it functions similar to figure 1 given above. Although there is at
least one (may be more) interpreter of C/C++ that exists as well. Your C/C++
source file(s) are converted to .obj code, and then a linker converts it to an
executable code. This executable code may be run on the host computer. Both the
.obj and the executable code are machine platform/dependent. The exe file can
only be run on a particular hardware and on a particular operating system.
There are compilers available for almost all the known combination of operating
system-hardware. If you have Linux running on Intel then the required compiler
usually comes as a part of installation package of Linux. If you have Windows
running on Intel, then you can use one of many compilers such as Borland's C++
or Microsoft's C++ compilers. Similarly a C/C++ compiler exists for Apple
Macintosh as well. So the only thing in your C/C++ program that seems to be
portable and platform independent is the actual source code - sorry to
disappoint you here!!!. Even this statement is only partially correct. Your
C/C++ code will only be portable if you have only used ANSI C standards. With
various vendor specific extensions of C/C++, it is highly unlikely that your
C/C++ code would automatically compile for all the platforms. So if you want to
ensure that your code compiles on ALL the platforms; then before incorporating
any API or function you should ensure that it is a standard and not vendor
specific. Usually the GUI functions available in C/C++/VC++ are always platform
dependent. So a simple MessageBox( ) API that you are so accustomed to in your
VC++, will not work in Unix. As a matter of fact much of what you code in VC++
will not work on any other platform - even Windows NT applications may not run
on Windows 2000 and vice versa. So although C/C++ results in one of the most
efficient executables - it falls down on its face when it comes to
platform-independence. While this shortcoming of C/C++ was well known to all,
it did not pose any problem until the Internet became a household tool. The
Internet brought with itself the need to be able to have a single application
run on multiple platforms without any changes. This is when Sun rose to the
occasion and developed Java.
A Java programmer
writes his code in a file with an extension .java. The source file will import
several Java framework classes/packages/libraries e.g. java.lang, java.utils
etc. In order for the programmer to produce a java file; he must have the JDK
(Java Development Kit) installed on his/her computer. The JDK is a
comprehensive set of software that includes all the bits and pieces required
for developing Java applications. These includes the JVM (Java Virtual
Machine), JRE (Java Runtime Environment; actually the JVM is a part of the JRE
), Java packages and framework classes, javac (the java compiler), and the Java
Debugger.
Once the program is
completed the programmer would compile the java source code using the java
compiler. The output of the compiler is a .class file.
So if you have put
your code in a file named Test.java; you would use the javac
program (the Java compiler) to compile your source file(s) into a class file
named Test.class.
Your Test.java
is a Java source text file while the Test.class file is in an
intermediate Java-byte code file, this file is actually the machine independent
intermediate code that can be executed on any computer with the JRE installed.
To run your Test.class
file you will use the Java Runtime Environment. Use the java command to
run the test file.
Given above is an
extremely simplified discussion of how to run a Java program. But before you
can run your Java programs you will have to set your CLASSPATH (an environment
variable) to point to all the referenced libraries/packages. You will also have
to use javac with appropriate switches and arguments to properly compile
your Test.java file.
The basic idea is
that in your Java program you will use Java framework
classes/packages/libraries or even third party packages (e.g. import
com.wrq.apptrieve.*" will tell the compiler that you will be referencing
the classes in this package). The compiler needs to be aware of the location of
these packages in order to successfully compile "Test.java".
Once compiled the JRE would also need an access to these external packages to
be able to run your program successfully. The JRE comes with the basic
framework classes/packages so that the JRE is already aware of these packages;
however for third party/external packages you will have tell JRE where to find
them by setting the CLASSPATH properly.
Once the JRE locates
all the necessary packages/files/libraries it can then run your program.
What gives Java the
platform independence is the ubiquity of JRE. JREs are available for most of
the commercial and popular platforms. What this means to a programmer is that
he/she needs to code once and the same program will run on any platform. This
is unlike the program written in Visual C++/Visual Basic etc. which can only
run on the targeted platform.
Before I discuss the
JVM in details, let me clarify a few related terms.
- Java Development Kit (JDK): This includes
ALL the basic Java framework packages, a compiler (javac), JRE, a JVM,
debugger etc. in short all you need to develop, debug, compile and run our
Java program.
- Java Runtime Environment (JRE): This is a
subset of the JDK. It does not include a debugger, compiler, and framework
classes. This includes the bare minimum that a computer needs in order to
run a .class file.
- Java Virtual Machine (JVM): JVM is a part
of JRE. The .class file is passed over to JVM which then runs the
program. The JRE ensures that the code does not violate any of the
security restrictions. Remember that the byte-code (.class file) is not
directly run on the host machine; it needs to be converted to the host
machine's language. This conversion is done by the JVM. While converting
the JVM ensures the security and may also optimize the code. There are
many commercial JVMs available in the market - different JVMs have
different capabilities, and varying degree of performance. In order to
produce efficient, code with minimum delay a JVM needs to have great
amount of intelligence built into it. Which would also make the JVM larger
in size. Remember that for a Java program to run, the JVM must be loaded
in the memory, and it is obvious that a large sized JVM would need much
more computer resources than a compact one. So there has to be a fine
balance between the size of a JVM and its capabilities. This is why a Java
program is always 30-70% slower than equivalent C++ program.
The initial JVMs were
extremely slow and were resource hungry - thus explaining the constant churning
of your hard-disk when you ran a Java program. In recent years lot of efficient
JVMs have surfaced. These JVMs use different compilation techniques to produce
efficient machine code in as less a time as possible. One such technique is
called Just-In-Time (JIT) compilation. This technique has also been used in
.NET.
Just In Time
Compilation (JIT): A detail discussion on Just-In-Time compilation may be found
in the references of this article. I will only discuss JIT briefly.
Just-in-time (JIT)
compilers promise to improve the performance of Java applications. Rather than
letting the JVM run byte code, a JIT compiler translates code into the host machine's
native language. Thus, applications gain the performance enhancement of
compiled code while maintaining Java's portability. Given below is a
pictorial description of how JIT works.
 A simple JVM without
the JIT enhancement would receive the java-byte-code (.class file), and would
convert an instruction to the host machine's machine code and would and run it
one-by-one, the overhead and delay in this approach is obvious and has already
been discussed in this article. But when a JIT is used, the JIT compiler
converts the byte-code .class file directly into the host machine's
native machine language and runs it directly - thus reducing the overhead.
All JVMs used today have JIT enhancement built into them by default, if you
don't want the JIT, you will need to tell the JRE implicitly through using
appropriate switches while running the programs.
A simple JVM without
the JIT enhancement would receive the java-byte-code (.class file), and would
convert an instruction to the host machine's machine code and would and run it
one-by-one, the overhead and delay in this approach is obvious and has already
been discussed in this article. But when a JIT is used, the JIT compiler
converts the byte-code .class file directly into the host machine's
native machine language and runs it directly - thus reducing the overhead.
All JVMs used today have JIT enhancement built into them by default, if you
don't want the JIT, you will need to tell the JRE implicitly through using
appropriate switches while running the programs.
Although the JIT
compile provides great improvement in program's execution speed, it involves
the overhead of converting the byte-code to native code at runtime. It is for
this reason that despite the JIT the Java programs are still slower that an
equivalent C/C++ program.
A Java Applet is a
special Java program that is only allowed to run inside a browser window. When
you embed a Java Applet in your web page, the browser sees the Applet tag and
downloads the byte code (the .class file) for the applet from the specified location.
Once the byte code is downloaded, the browser uses the JVM (included in the
browser itself) to run the Applet, ensuring that the Applet does not execute
any insecure APIs - mainly the APIs that access the client machine hardware.
Given the concept of
the JVM, it is obvious that any programming language that compiles into Java
byte code can use the JVM for running the program. We are all aware of how Java
code (.java) is converted into byte code (.class) which is then run by the JVM
on the host machine. What if we make a compiler of C++, that converts a C++
source file (.c or .cpp) into a java-byte code file (.class) rather than into
an .obj file. Theoretically it is possible, whether it is practical or not is a
different issue all together. In fact there have been many languages that have
compilers which produce java byte code that can then be run by the JVM. This article belittles Microsoft's claim that the CLR is
the only platform to support the language antagonism. JVM can also (and in fact
already is) be used by different languages
What is Microsoft's
Common Language Runtime (CLR)? It is the life line of .NET applications. Before
I describe the CLR - let's explain what is meant by runtime. A runtime is an
environment in which programs are executed. The CLR is therefore an environment
in which we can run our .NET applications that have been compiled to IL. Java
programmers are familiar with the JRE (Java Runtime Environment). Consider the
CLR as an equivalent to the JRE.

The above diagram
shows various components of the CLR.
The Common Type
System (CTS) is responsible for interpreting the data types into the common
format - e.g. how many bytes is an integer.
The second component,
the IL Compiler takes in the IL code and converts it to the host machine
language. The execution support is similar to the language runtime (e.g. in VB
the runtime was VBRunxxx.dll; however with VB.NET we do not need individual
language runtimes anymore).
Security component in
the CLR ensures that the assembly (the program being executed) has permissions
to execute certain functions. The garbage collector is similar to the garbage
collector found in Java. Its function is to reclaim the memory when the object
is no longer in use, this avoids memory leaks and dangling pointers. The class
loader component is similar to the class loader found in Java. Its sole purpose
is to load the classes needed by the executing application.
Here's the complete
picture.
The programmer must
first write the source code and then compile it. Windows programmers have
always compiled their programs directly into machine code - but with .NET
things have changed. The language compiler would compile the program into an
intermediate language "MSIL" or simply "IL" (much like Java
Byte code). The IL is fed to the CLR then CLR would use the IL compiler to
convert the IL to the host machine code.
.NET introduces the
concept of "managed code" and "unmanaged code". The CLR
assumes the responsibility of allocating and de-allocating the memory. Any code
that tries to bypass the CLR and attempts to handle these functions itself is
considered "unsafe"; and the compiler would not compile the code. If
the user insists on bypassing the CLR memory management functionality then he
must specifically write such code in using the "unsafe" and
"fixed" key words (see C# programmers guide for details). Such a code
is called "unmanaged" code, as opposed to "managed code"
that relies on CLR to do the memory allocation and de-allocation.
The IL code thus
produced has two major issues with it. First it does not take advantage of
platform specific aspects that could enhance the program execution. (for
example if a platform has some complicated graphics rendering algorithm
implemented in hardware then a game would run much faster if it exploit this
feature; however, since IL cannot be platform specific it can not take
advantage of such opportunities). Second issue is that IL can not be run directly
on a machine since it is an intermediate code and not machine code. To address
these issues the CLR uses an IL compiler. The CLR uses JIT compilers to compile
the IL code into native code. In Java the byte code is interpreted by a Virtual
Machine (JVM). This interpretation caused Java applications to run extremely
slow. The introduction of JIT in JVM improved the execution speed. In the CLR
Microsoft has eliminated the virtual machine step. The IL code is compiled to
native machine and is not interpreted at all. For such a compilation the CLR
uses the following two JIT compilers:
- Econo-JIT : This compiler
has a very fast compilation time; but it produces un-optimized code - thus
the program may start quickly but would run slow. This compiler is
suitable for running scripts.
- Standard-JIT: This compiler
has a slow compilation time; but it produces highly optimized code. Most
of the times the CLR would use this compiler to run your IL code.
- Install Time Compilation: This technique
allows CLR to compile your application into native code at the time of
installation. So the installation may take a few minutes more - but the
code would run at speeds close to a native C/C++ application.
Once your program has
been compiled into host machine code, it can begin execution. During execution
the CLR provides security and memory management services to your code (unless
you have specifically used unmanaged code).
It is clear from the
above discussion; that Microsoft has done what it does best. It has observed
the JRE/JVM for four years; and then has come up with a more efficient and
stable runtime environment that builds on top of the strengths of JRE/JVM and
removes its shortcomings.
So what should you
expect when you start using the CLR?. You should most definitely expect your
programs to run faster than an equivalent Java program but your program would still run
slower than an equivalent C/C++ program - or any other program that is compiled
into machine language. That's a limitation that ALL interpreted languages have,
and that's the price you pay for platform independence.
JVM is available for
most of the platforms (hence your Java program is really platform independent);
while CLR (at the time of writing of this article) is only available for
Microsoft Windows platforms (hence a .NET program is not really platform
independent, it only promises to be platform independent). Microsoft has not
unveiled any future program to develop CLR for other platforms; though it is
inevitable that third parties would come up with CLRs for non-Microsoft
platforms.
No comments:
Post a Comment